The short version
Swing Finder runs two complementary scoring systems over every stock:
| System | Question it answers |
|---|---|
| ML rank scores (this page) | Across all stocks today, which ones is the model most confident about? |
| Statistical probability (explained here) | For a specific trendline's feature pattern, what fraction of historical look-alikes held vs broke? |
The ML scores read every stock straight from its price action and rank tickers relative to each other. The statistical model speaks about a single line in isolation. They are best read together.
The ranking model
A single model reads every stock's recent price action and gives it one score:
- High means the model sees a strong setup to rise.
- Low means expected weakness or downside.
- Around zero means no strong view.
Sort the universe by that score and the top of the list is the model's highest-conviction set. The evidence below shows how well that ordering holds up out of sample.
How to read a score
What that means in practice:
- Higher beats lower. +1.20 is a stronger pick than +0.40 and earns more on average; the gap between scores is not itself a percentage.
- "Top X%" badges tell you where a stock sits in today's cross-section of the whole universe. A Top 1% badge means it is among the highest-scored names right now.
- The sign shows the model's lean (positive = expected strength, negative = expected weakness), but the percentile matters more than the sign alone.
- "Top pick" still needs your judgement. A high score means the model recognises a strong setup, not "buy this". On a broadly weak day the top pick is just the least weak option.
The evidence
Every chart here is computed on an out-of-sample holdout: signals the model never trained on. Where returns are shown they are realized forward returns (buy the next open, hold), net of the 0.70% round-trip cost. Click any chart to enlarge.
It separates winners from losers
Sort the holdout by score into ten deciles and look at the share of trades that rose. The win rate climbs cleanly from the lowest-scored decile to the highest: the ranking reliably sorts likely winners from likely losers.

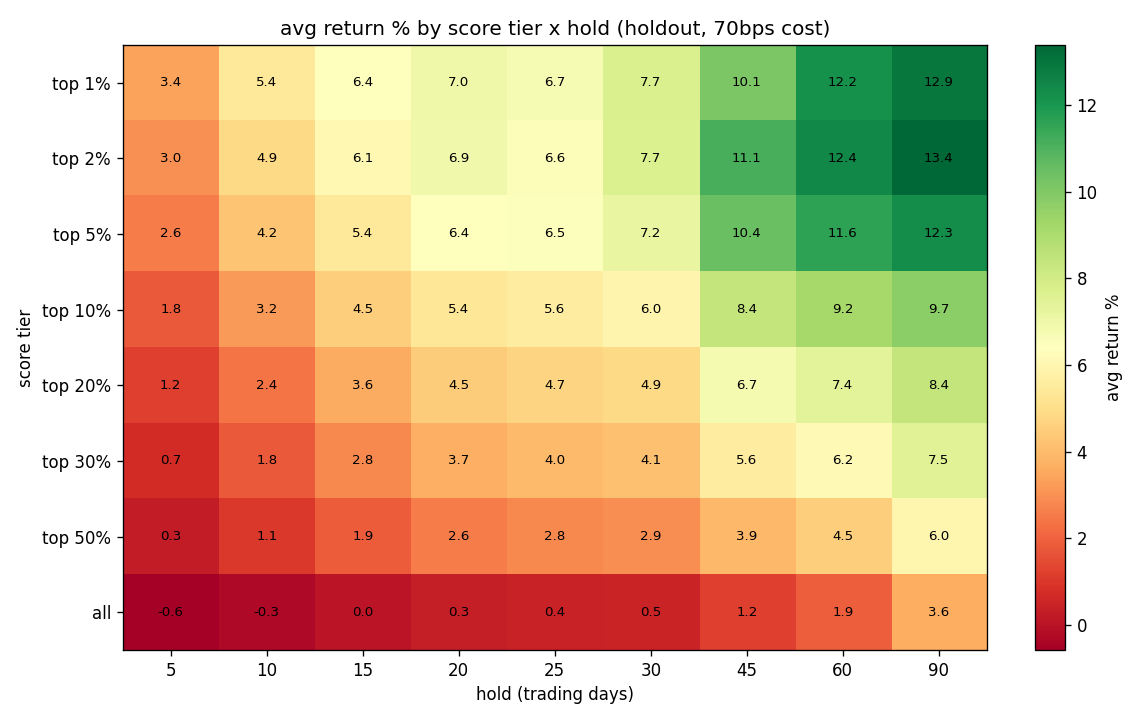
Selectivity and patience both pay
Realized forward return by how selective you are (top 1% of scores down to the whole field) and how long you hold. The bottom "all" row is the no-model baseline: what a random pick earns from market drift. Both being more selective and holding longer raise the return, monotonically. The top 1% held ~90 days averages about +15% vs ~+4.5% for the field.
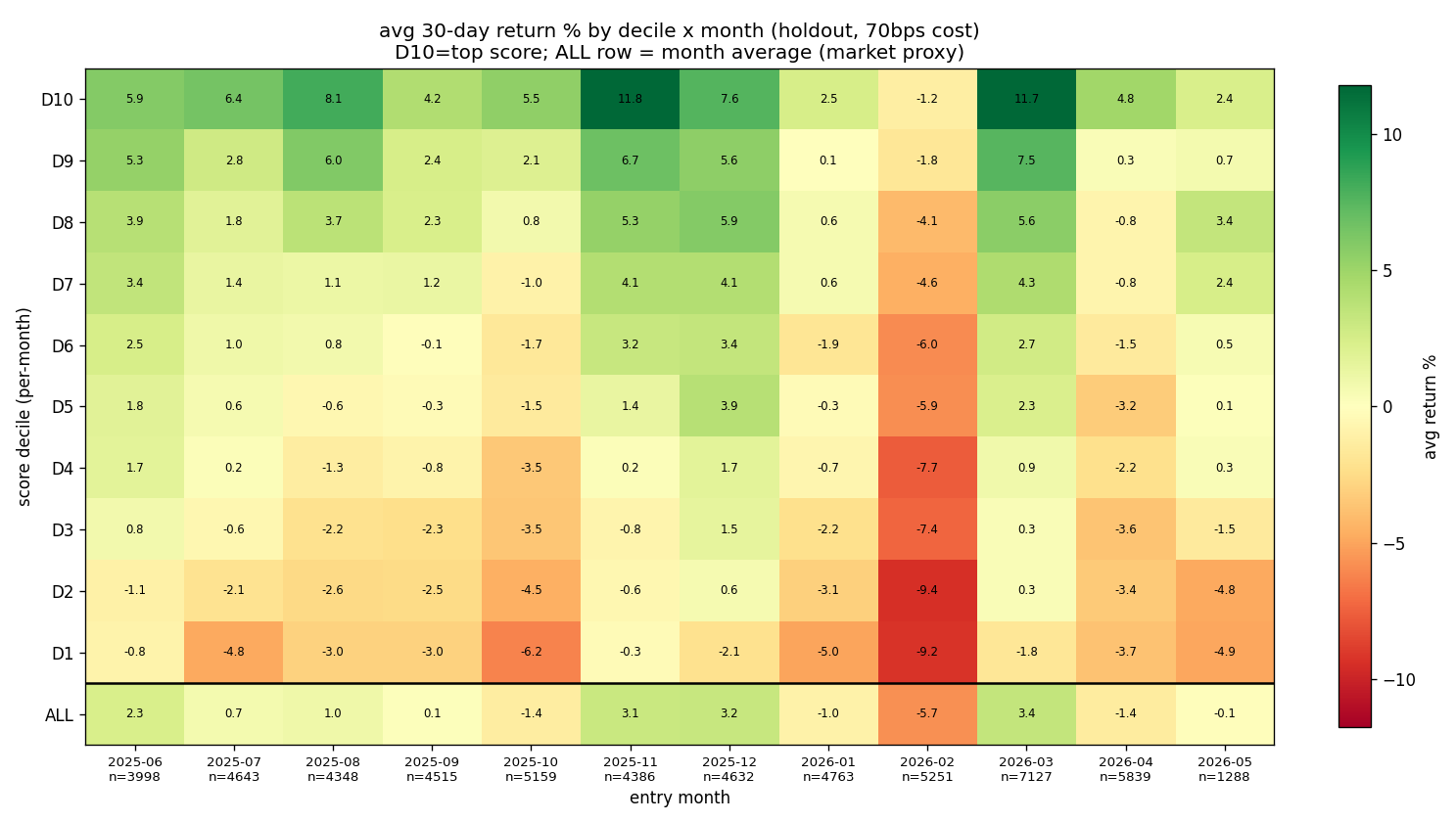
It held up in the downturn
Per-month deciles; the bottom ALL row is that month's average (a market proxy), so red ALL cells are the down months. The top-minus-bottom spread was positive in every month. In the worst one, with the market down 5%, the top decile was roughly flat and the spread held. The edge is defensive, not a bull-market artifact.
When to sell
Average realized return by exit rule (hold, stop-loss, profit target, bracket, trailing stop) and max hold, on the top-decile trades.

Caveats and things to remember
The raw score isn't a return forecast
A score of +1.20 does not mean "12% expected return". It is an uncalibrated ranking value: high scores rank above low scores, but the spacing does not translate to a return. The meaningful quantity is the percentile the score puts the stock in. You cannot read the raw value as a percentage, and the raw scale is not reliable to compare across very different market conditions.
The holdout is real but short
The evidence above is genuinely out-of-sample, but it covers a single year that spans one notable downturn, not a multi-cycle test. Returns are net of the 0.70% Belgian round-trip tax (0.35% each side), entries are at the next open, and thin names can fill worse than the test assumes. Returns are also spread broadly across many names rather than carried by a few, which argues for diversifying over many positions rather than big single bets.
Survivorship
The model's view is shaped by the tickers currently in our universe. Stocks delisted, acquired, or otherwise removed before they reached our coverage are not represented.
Combine with the statistical model
For an active trendline, the statistical model tells you how that line's specific feature combination has historically behaved. When the ML rank score is high and the line's statistical hold-rate is well above the base rate, both signals agree, and that is stronger conviction than either on its own.